Blog
Supervised Learning – tell me more…

Let’s take a wander into what is meant by “Supervised Learning” which folds under the category of ‘Machine Learning‘. Machine Learning comprises of hundreds or different algorithmic approaches, see it as the ability for a machine to learn from data without explicit instruction. However all Machine learning can be divided into a few overarching categories – one of which is “Supervised learning”. Unsupervised, Semi-supervised, reinforcement learning, and Q Learning will be covered by “Data Science Frontiers” soon.
This article will take the reader on a basic introduction to Supervised Learning. So let’s make a start.
Supervised Learning
Most Machine Learning that is driving value in the real world are Supervised Learning models.
Supervised Learning mirrors the learning process of how we learn via a series of inputs and outputs that we start to group and categorise in our minds from being told how things correlate and fit together. Similarly, in supervised learning, once we comprehend how certain inputs are associated with specific outputs we can train the machine learning model accordingly.
For example, when you see adverts online we tend to ignore some and click on others that interest us. Over time, the model begins to start building up an understanding of our preferences, gradually categorising what we will likely be interested in for future advertisements. The model can start to associate information about that interaction to potential outcomes.
To train the model, we feed it a dataset containing labelled inputs and outputs, enabling the model to learn a pattern and can start associating the inputs to likely outputs, typically a single output. Continuously supplying the model with new, correctly labelled outputs aids in its improvement by facilitating the learning of underlying patterns.
If the model makes a mistake, this can then be flagged, allowing the model to learn and adjust, reducing errors progressively.
Input data is referred to as the independent variable or Features displayed as ‘X’
Output data is referred to as the dependent variable or Labels displayed as ‘Y’.
The independent variables influence the dependent variables.
Let’s look at some examples to help our understanding. Object Identification is a popular application of Artificial Intelligence. Object Recognition is exactly what it states, the ability to identify objects through specific attributes. For example, this can be as simple as feeding images into a model to flag whether a cat is detected or not in the provided image. The independent variables (x) could be down to the shape, size and colour of nose, the shape of face, and even the location of the animal amongst many other attributes. These independent variables then effect the dependent variable (y), is the image a cat or not.
Once a sizeable quality quantity of labelled input (x) training data sets, we will cover what is classed as ” sizeable quality quantity” in a later article, has been fed through the model with example outputs (y) the machine will then leverage the model to start predicting outputs successfully.

Arguably - this is more like a classifier image so I will soon be updating the image with something more applicable.
Another example of Supervised Learning approaches, is having a model that can value a house based on a database of attributes from historic house sales. If we know size, location and demand are the key drivers in house price valuations, then if we also have a database containing a labelled dataset of recent house sales based on these various attributes we should be able predict the value. We would need to use input data of Location, Size & Demand as ‘X’ (Independent Variables) to produce the output of House Value as ‘Y’ (Dependent Variable). The model works backwards to understand and determine the relationships between the the output, house value, and the input, house characteristics.
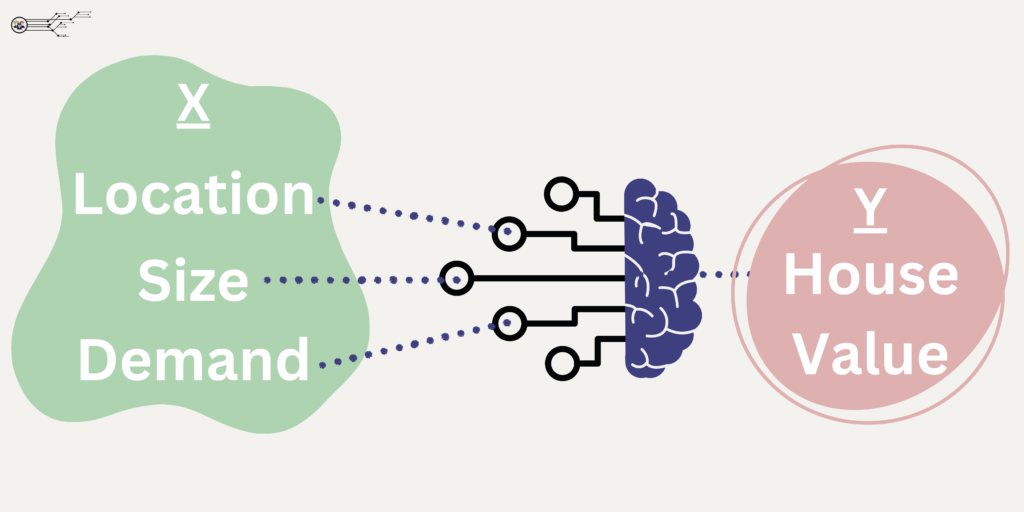
An incredibly important part of Supervised Learning is that the model must be built with labelled data, the model needs to have labelled input and output values to be trained appropriately. This is commonly referred to in the wonderful world of Data Science as a “Labelled Data Set”.
Categorisations of Supervised Learning
Supervised learning can be split into two types:
-
- Classification
- Regression
These both, in turn will be covered later by the “Data Science Frontiers”.
Thank you for reading this article – please do leave feedback so we can continuously improve the site. See it as our own way of labelling our model to better train it.